Mastering HPC Monitoring Data: From Zero to Hero with LLview
Monday, May 13, 2024 3:00 PM to Wednesday, May 15, 2024 4:00 PM · 2 days 1 hr. (Europe/Berlin)
Foyer D-G - 2nd floor
Research Poster
System and Performance Monitoring
Information
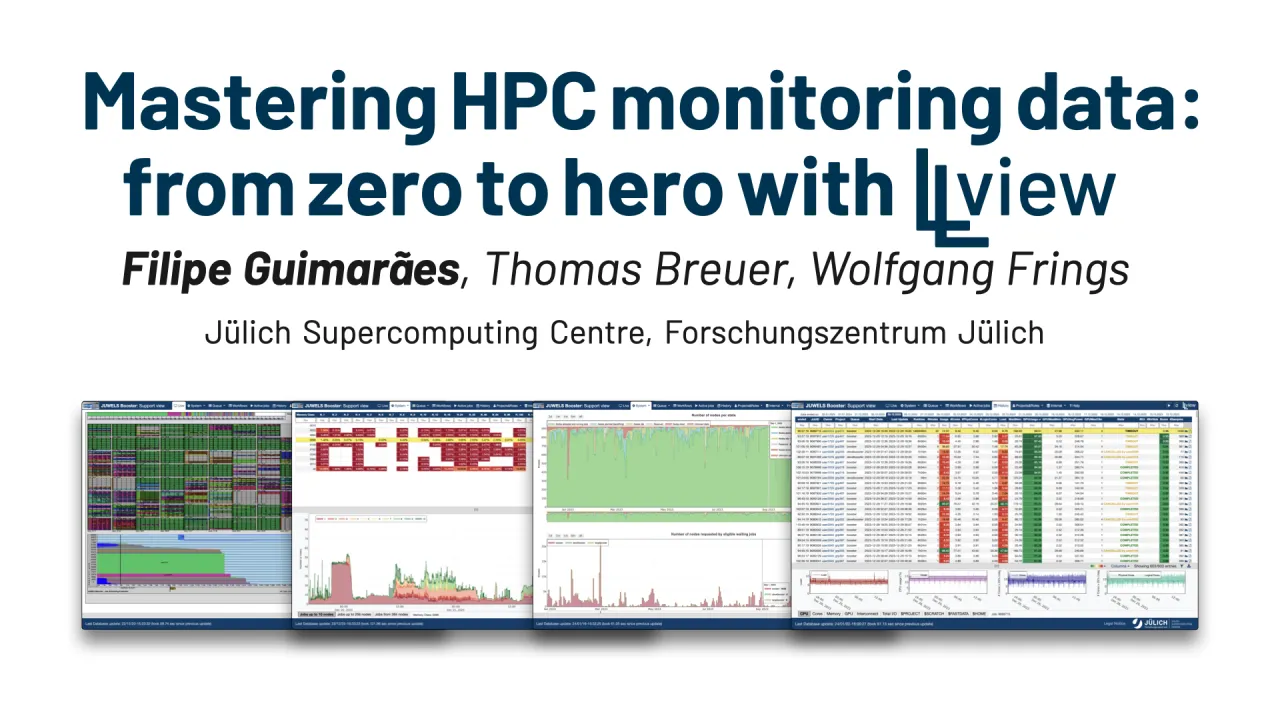
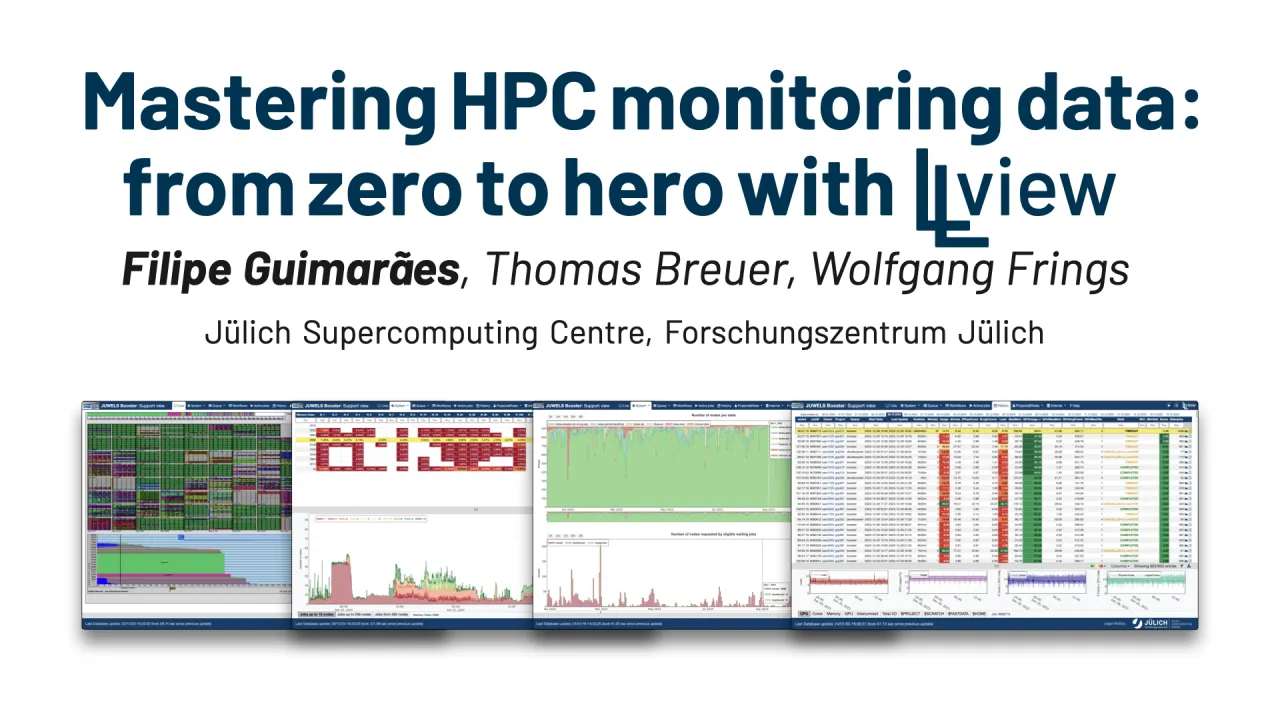
Poster is on display and will be presented at the poster pitch session. Monitoring large high performance computer systems requires not only a constant watch for system errors, but also thorough scrutiny of jobs with wrong setups, not making good use of the resources or with optimisation opportunities. To address these challenges and facilitate problem identification and resolution, we designed and implemented the LLview infrastructure. Through the integration of diverse pre-existing metrics from the system into a visually sophisticated and interactive web portal, this solution establishes itself as a consolidated central hub for users. In this poster, we demonstrate how LLview is used in all production systems at the Jülich Supercomputing Centre to identify and address a spectrum of critical issues. These encompass instances of underutilized resources, GPU-related anomalies leading to slow-down of jobs, memory leaks, and intricate job step failures. Our results underscore LLview's efficacy as a comprehensive monitoring solution, adept at detecting and resolving complex issues within dynamic environments. An internal view of how the data flow and update cycles is also presented, explaining how its scalability is achieved to provide near real-time information to the end-user, and making it ready for Europe’s first exascale computer, JUPITER. Recent additions to the data flow provides the possibility of regular analysis with AI models, automatically supplying additional information to the responsible people and improving even further the supplied assistance. LLview has been further developed within different projects, such as SiveGCS (NRW), DEEP-SEA, IO-SEA and EUPEX (EU). With its open source release, we also expect to collaborate with other HPC centers worldwide.Contributors: