Co-Scheduling - Towards Energy Efficient HPC Operations
Wednesday, June 24, 2026 3:45 PM to 5:15 PM · 1 hr. 30 min. (Europe/Berlin)
Foyer D-G - 2nd Floor
Women in HPC Poster
Energy Efficiency and SustainabilityResource Management and SchedulingSystem and Performance Monitoring
Information
Poster is on display and will be presented at the poster pitch session.
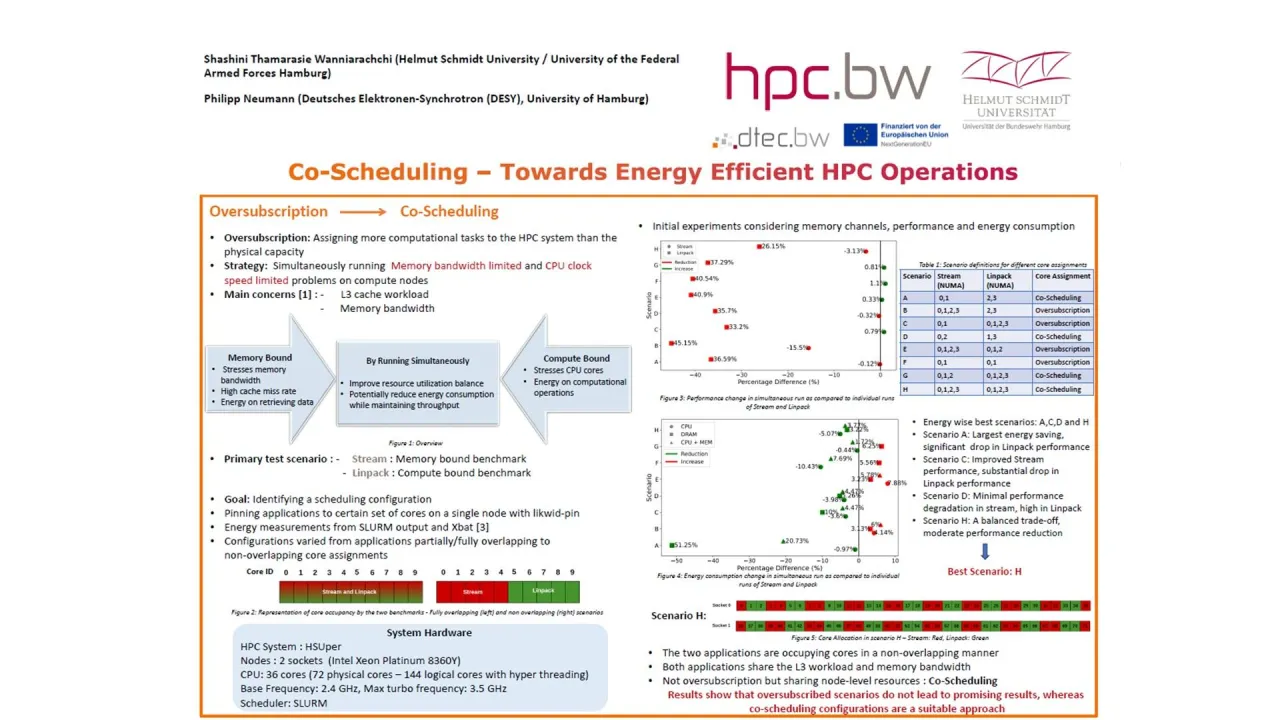
With the growing usage of high-performance computing (HPC) across multiple application domains, energy consumption has become a topic impossible to ignore. Among various energy saving mechanisms, oversubscription: allocating more computational tasks than the physical capacity of the system, has emerged as a suitable approach. In modern HPC nodes, which contain many cores with shared memory channels and L3 cache, memory bandwidth and cache contention are key performance and energy bottlenecks.
HPC workloads can broadly be classified into two. Memory bound applications stress memory bandwidth and exhibit high cache miss rates, consuming significant energy for data retrieval. In contrast, compute bound applications primarily stress CPU cores, have a high compute-to-memory ratio, and spend most of their energy on computation. These complementary resource demands create an opportunity to run such workloads simultaneously, sharing system resources more efficiently through oversubscription.
This work investigates oversubscription through co-scheduling of HPC workloads. All experiments were conducted on the HSUper HPC system, which consists of two sockets with 36 cores each (72 physical cores total), using SLURM as the scheduler. As an initial test case, we used Stream, a memory bound benchmark, and Linpack, a compute bound benchmark. The goal was to identify an effective scheduling configuration for oversubscription. Both applications were pinned to specific cores on a single node using likwid-pin.
Multiple configurations were evaluated, ranging from fully overlapping core assignments to completely non-overlapping ones. These configurations also varied in how memory channels were saturated. In total, eight scenarios were tested, and performance and energy consumption were measured. Results showed that the optimal configuration involved running the two applications on non-overlapping cores while saturating all memory channels. In this scenario, Stream experienced a performance degradation of 3.13% and Linpack 26.15%, while overall energy consumption was reduced by 3.7%. Although the cores were non-overlapping, the L3 cache and memory bandwidth were still shared, making this approach, co-scheduling, even though it’s not pure oversubscription.
After identifying a suitable configuration, the co-scheduling study was extended to real applications. In the next experiment, Stream was replaced by Lesocc (Large Eddy Simulation on Curvilinear Co-ordinates), a 3D finite volume code for computational fluid dynamics on block-structured grids with non-orthogonal and non-staggered arbitrary geometry. Lesocc was co-scheduled alongside Linpack. The results showed that co-scheduling reduced the total runtime by 10 minutes and lead to a reduction of 20% in energy consumption. As expected, performance degradation was observed in both applications caused by resource contention. However, the reduction was within a tolerable range considering the substantial energy savings achieved.
Overall, these results demonstrate that co-scheduling complementary workloads can significantly improve the energy efficiency of HPC systems, at the cost of moderate performance degradation. Ongoing work includes deeper analysis of L3 cache behaviour and extending to other compute bound applications. Ultimately in future, we aim at generalizing the applicability and providing a co-scheduling configuration to HSUper users.
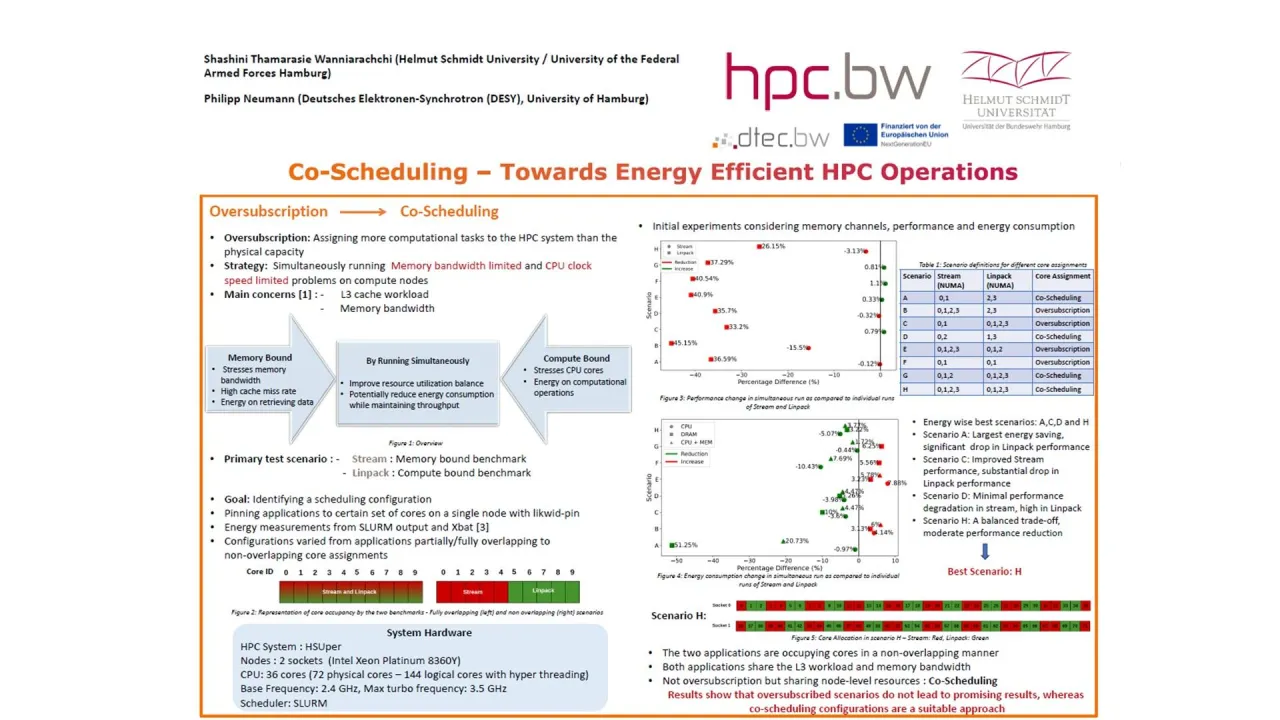
With the growing usage of high-performance computing (HPC) across multiple application domains, energy consumption has become a topic impossible to ignore. Among various energy saving mechanisms, oversubscription: allocating more computational tasks than the physical capacity of the system, has emerged as a suitable approach. In modern HPC nodes, which contain many cores with shared memory channels and L3 cache, memory bandwidth and cache contention are key performance and energy bottlenecks.
HPC workloads can broadly be classified into two. Memory bound applications stress memory bandwidth and exhibit high cache miss rates, consuming significant energy for data retrieval. In contrast, compute bound applications primarily stress CPU cores, have a high compute-to-memory ratio, and spend most of their energy on computation. These complementary resource demands create an opportunity to run such workloads simultaneously, sharing system resources more efficiently through oversubscription.
This work investigates oversubscription through co-scheduling of HPC workloads. All experiments were conducted on the HSUper HPC system, which consists of two sockets with 36 cores each (72 physical cores total), using SLURM as the scheduler. As an initial test case, we used Stream, a memory bound benchmark, and Linpack, a compute bound benchmark. The goal was to identify an effective scheduling configuration for oversubscription. Both applications were pinned to specific cores on a single node using likwid-pin.
Multiple configurations were evaluated, ranging from fully overlapping core assignments to completely non-overlapping ones. These configurations also varied in how memory channels were saturated. In total, eight scenarios were tested, and performance and energy consumption were measured. Results showed that the optimal configuration involved running the two applications on non-overlapping cores while saturating all memory channels. In this scenario, Stream experienced a performance degradation of 3.13% and Linpack 26.15%, while overall energy consumption was reduced by 3.7%. Although the cores were non-overlapping, the L3 cache and memory bandwidth were still shared, making this approach, co-scheduling, even though it’s not pure oversubscription.
After identifying a suitable configuration, the co-scheduling study was extended to real applications. In the next experiment, Stream was replaced by Lesocc (Large Eddy Simulation on Curvilinear Co-ordinates), a 3D finite volume code for computational fluid dynamics on block-structured grids with non-orthogonal and non-staggered arbitrary geometry. Lesocc was co-scheduled alongside Linpack. The results showed that co-scheduling reduced the total runtime by 10 minutes and lead to a reduction of 20% in energy consumption. As expected, performance degradation was observed in both applications caused by resource contention. However, the reduction was within a tolerable range considering the substantial energy savings achieved.
Overall, these results demonstrate that co-scheduling complementary workloads can significantly improve the energy efficiency of HPC systems, at the cost of moderate performance degradation. Ongoing work includes deeper analysis of L3 cache behaviour and extending to other compute bound applications. Ultimately in future, we aim at generalizing the applicability and providing a co-scheduling configuration to HSUper users.
Format
on-demandon-site
